Low Hanging Fruit
Introduction
In the previous post Creating a Roadmap, we established a plan for this blog. To give ourselves the best chance of success, and to ensure the longevity of this project, it is important to address areas of friction. These are the areas that distract (even detract) from important activities centred around this project. Activities such as research, planning, scoping, building and consequently distilling information in the form of writing these posts.
This post is going to document some house keeping tasks that should alleviate the friction. We will also touch on one or two technical points. In the end, we want to set ourselves up in such a manner, that the majority of our effort is spent on the important activities.
Thus, the title of this post, “Low Hanging Fruit”. These are (relatively) easy things we can accomplish which will assist us in the long run.
Let us get started!
The classic to-do list
Here are a couple of the chores that will be tackled as part of this post.
- Save what matters
- Streamline the “start”
- Make the upload easier
Each one of these items will have their own section, in which we will highlight the frustration and remedy it.
Save what matters
We will start with the easiest item on the list. Let us unpack the frustration.
Until now, when the writing part of a post is complete, a program (we touch on this later) is used to convert the markdown text, as an example:

to files that make up a website. All of these files are then version controlled (saved).
Think of this in terms of the y is a function of x statement. Where y would be the site, as you see it, and x would be the markdown files that contain the actual “content”.
By saving the output y, we are locking ourselves into the function that generated y. One could see, perhaps with some reflection, that this is not “future proof”. If for some reason, the “function” stops, well, functioning - it would require immense amounts of effort to retrieve x (our original thoughts and writings!). We don’t “own” the function, we have some say in how it operates, but it is not ours. Clearly, it is more important for us to rather save (or version control) the input (x). This way, we can experiment, at will, with anything that will change the output. We can rest easy knowing that our original thoughts and writings are safe.
The fix here is easy - throw away everything unnecessary. We will now only save our writings, the markdown files. This saves us time and we have also reduced the clutter in our repository.
- Save what matters - done
Streamline the “start”
Another easy item to tackle. Significant time passes between writing phases of the blog. Weeks may pass before sentences start forming. It becomes crucial then, when the writing process is under-way, that no time is wasted on Googling, and reading through the documentation of the static site generator (Hugo) to remember how it works. Hugo is a core part of generating the website you are seeing (recall the former statement y = f(x), Hugo is the function!). In the future we will be writing our own generator - but to have a means of delivering content, we need to continually remember how Hugo works.
The easiest solution would be to write a “cheat-sheet” on a sticky note and having it in eyesight. We can do one better though! We largely interact with Hugo in the command terminal. Typing the command hugo help will print out all of the Hugo commands for reference - but we are largely interested in three basic commands. Our three most used Hugo commands are:
- Command to create the file(s) for a new post
- Command to host our blog locally, so that we can proof read, and see what the post looks like in a browser
- Command to generate the website (this is what we upload to the internet. We touch on this in the next section, Make the upload easier)
Since we interact with Hugo in the command terminal, we can write a custom helper function to simply print a reminder of what these commands are. This makes referencing them easy, and if needed, we can always add additional commands to the list.
hugo-cheatsheet() {
# Color codes
RED='\e[31m'
BLU='\e[34m'
GRN='\e[32m'
DEF='\e[0m'
echo -e ${DEF}Create new post : ${GRN}hugo new content ${RED}'path-to-posts/'${BLU}'filename.md'
echo -e ${DEF}Local dev test : ${GRN}hugo server -D
echo -e ${DEF}Prepare for deploy: ${GRN}hugo${DEF}
}
Now, when we are in our terminal in need of a refresher, we can simply type hugo-cheatsheet and have a useful reminder of which commands to utilize:
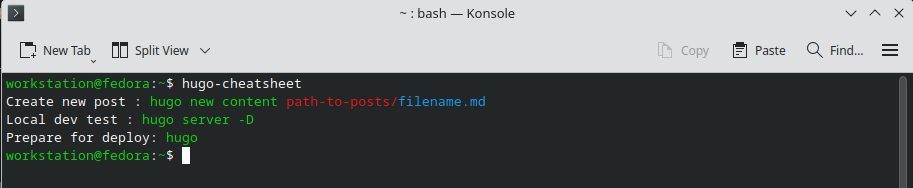
In other cases, when we need to know extra information, we can read through the documentation.
- Streamline the “start” - complete
Make the upload easier
For a technical blog, we finally get to do something technical. To make the blog posts available to the internet, currently, all of the required files and folders are manually copied into a Google Storage bucket. Currently this is around 22 files, and 13 sub directories, which is steadily increasing as we deliver more content. The Google interface for uploading these files, is not entirely user friendly, and does not allow for easy “drag and drop” replacements. This makes the upload process time consuming, and error prone. Missing a file, or copying an incorrect file could mean that the entire blog becomes unavailable.
The fix for this problem, should be clear. Write a small program to upload all the relevant files to where they need to be. This way, we have a reliable, reproducible and (hopefully) less error prone way of delivering content.
It was mentioned that this blog would be focused around .NET programming. Naturally, you might expect C# code to be written to automate this process. While, it is absolutely possible to use C# to solve this problem, we will be utilizing Python. There are a couple of reasons for choosing Python, which is by no means implying Python (or C#, or [insert any language]) is better. It simply felt like a logical choice.
Pythonis an interpreted language. This means the code is executed line by line. This should make the development and debugging cycle faster.C#is a compiled language. Meaning the code is translated into an intermediate language, and then to machine code. This will generally lead to better runtime performance. Due the “scope” of this task we are automating, concerning ourselves with performance is unnecessary. Point 1 forPython.Pythonis known for clean syntax, that emphasizes readability. It often also requires a lot less “boilerplate” code.C#syntax is more verbose, utilizing a lot of curly braces{}and semicolons;to delineate code blocks. So, for the sake of the readability (this is a blog after-all), Point 2 forPython.
Let us take a step, back, and think about what we want to do. We want to take all of the files that Hugo generates and upload them to our Google Storage Bucket. Sounds straightforward.
Below is the Python that achieves what we are looking for.
from google.cloud import storage
import pathlib
# The identifier of the bucket to upload files to
storage_bucket_id = "<storage-bucket-id>"
# Path to the local directory containing files to upload
public_folder_path = "<path-to-hugo-generated-content>"
# Find the local files to upload
folder = pathlib.Path(public_folder_path)
# Recursively yield path objects of the directory
objects_in_folder = list(folder.rglob("*"))
# Filter for files only
files_to_upload = filter(lambda x: x.is_file(), objects_in_folder)
# Upload files to Google Storage Bucket
storage_client = storage.Client()
bucket = storage_client.bucket(storage_bucket_id)
for file in files_to_upload:
blob_name = str(file.absolute()).removeprefix(public_folder_path).lstrip('/')
print("Creating blob: {}".format(blob_name))
blob = bucket.blob(blob_name)
blob.upload_from_filename(str(file))
print("Uploaded file: {}".format(file))
Now each time there is new content to upload, we can simply run our Python script. This not only saves us time, but also makes the process a lot less error prone!
- Make the upload easier - done!
Conclusion
Admittedly, chores can be boring and not as exciting as doing something new, but we have set ourselves up to make future posts a lot easier to write, save and upload. The less frustrations we deal with while writing, researching and working on future content, the more likely it is that we will continue to do so. As time moves on, new chores will arise, and we will deal with those too. Hopefully this post sparked a bit of curiosity - or perhaps a bit of reflection on the frustration areas in life that are getting in the way of the things that matter.
Our next series of posts will likely dive into the realm of content generation, or the construction of our own website for our generated content. It will be technical, it will be detailed, even potentially spanning multiple posts, but above all, we will strive to make it entertaining!